
[ad_1]
Development of Ethereum has been progressing increasingly quickly this past month. The release of PoC5 (“proof of concept five”) last month the day before the sale marked an important event for the project, as for the first time we had two clients, one written in C++ and one in Go, perfectly interoperating with each other and processing the same blockchain. Two weeks later, the Python client was also added to the list, and now a Java version is also almost done. Currently, we are in the process of using an initial quantity of funds that we have already withdrawn from the Ethereum exodus address to expand our operations, and we are hard at work implementing PoC6, the next version in the series, which features a number of enhancements.
At this point, Ethereum is at a state roughly similar to Bitcoin in mid-2009; the clients and protocol work, and people can send transactions and build decentralized applications with contracts and even pretty user interfaces inside of HTML and Javascript, but the software is inefficient, the UI underdeveloped, networking-level inefficiencies and vulnerabilities will take a while to get rooted out, and there is a very high risk of security holes and consensus failures. In order to be comfortable releasing Ethereum 1.0, there are only four things that absolutely need to be done: protocol and network-level security testing, virtual machine efficiency upgrades, a very large battery of tests to ensure inter-client compatibility, and a finalized consensus algorithm. All of these are now high on our priority list; but at the same time we are also working in parallel on powerful and easy-to-use tools for building decentralized applications, contract standard libraries, better user interfaces, light clients, and all of the other small features that push the development experience from good to best.
PoC6
The major changes that are scheduled for PoC6 are as follows:
- The block time is decreased from 60 seconds to 12 seconds, using a new GHOST-based protocol that expands upon our previous efforts at reducing the block time to 60 seconds
- The ADDMOD and MULMOD (unsigned modular addition and unsigned modular multiplication) are added at slots 0x14 and 0x15, respectively. The purpose of these is to make it easier to implement certain kinds of number-theoretic cryptographic algorithms, eg. elliptic curve signature verification. See here for some example code that uses these operations.
- The opcodes DUP and SWAP are removed from their current slots. Instead, we have the new opcodes DUP1, DUP2 … DUP16 at positions 0x80 … 0x8f and similarly SWAP1 … SWAP16 at positions 0x90 … 0x9f. DUPn copies the nth highest value in the stack to the top of the stack, and SWAPn swaps the highest and (n+1)-th highest value on the stack.
- The with statement is added to Serpent, as a manual way of using these opcodes to more efficiently access variables. Example usage is found here. Note that this is an advanced feature, and has a limitation: if you stack so many layers of nesting beneath a with statement that you end up trying to access a variable more than 16 stack levels deep, compilation will fail. Eventually, the hope is that the Serpent compiler will intelligently choose between stack-based variables and memory-based variables as needed to maximize efficiency.
- The POST opcode is added at slot 0xf3. POST is similar to CALL, except that (1) the opcode has 5 inputs and 0 outputs (ie. it does not return anything), and (2) the execution happens asynchronously, after everything else is finished. More precisely, the process of transaction execution now involves (1) initializing a “post queue” with the message embedded in the transaction, (2) repeatedly processing the first message in the post queue until the post queue is empty, and (3) refunding gas to the transaction origin and processing suicides. POST adds a message to the post queue.
- The hash of a block is now the hash of the header, and not the entire block (which is how it really should have been all along), the code hash for accounts with no code is “” instead of sha3(“”) (making all non-contract accounts 32 bytes more efficient), and the to address for contract creation transactions is now the empty string instead of twenty zero bytes.
On Efficiency
Aside from these changes, the one major idea that we are beginning to develop is the concept of “native contract extensions”. The idea comes from long internal and external discussions about the tradeoffs between having a more reduced instruction set (“RISC“) in our virtual machine, limited to basic memory, storage and blockchain interaction, sub-calls and arithmetic, and a more complex instruction set (“CISC“), including features such as elliptic curve signature verification, a wider library of hash algorithms, bloom filters, and data structures such as heaps. The argument in favor of the reduced instruction set is twofold. First, it makes the virtual machine simpler, allowing for easier development of multiple implementations and reducing the risk of security issues and consensus failures. Second, no specific set of opcodes will ever encompass everything that people will want to do, so a more generalized solution would be much more future-proof.
The argument in favor of having more opcodes is simple efficiency. As an example, consider the heap). A heap is a data structure which supports three operations: adding a value to the heap, quickly checking the current smallest value on the heap, and removing the smallest value from the heap. Heaps are particularly useful when building decentralized markets; the simplest way to design a market is to have a heap of sell orders, an inverted (ie. highest-first) heap of buy orders, and repeatedly pop the top buy and sell orders off the heap and match them with each other while the ask price is greater than the bid. The way to do this relatively quickly, in logarithmic time for adding and removing and constant time for checking, is using a tree:
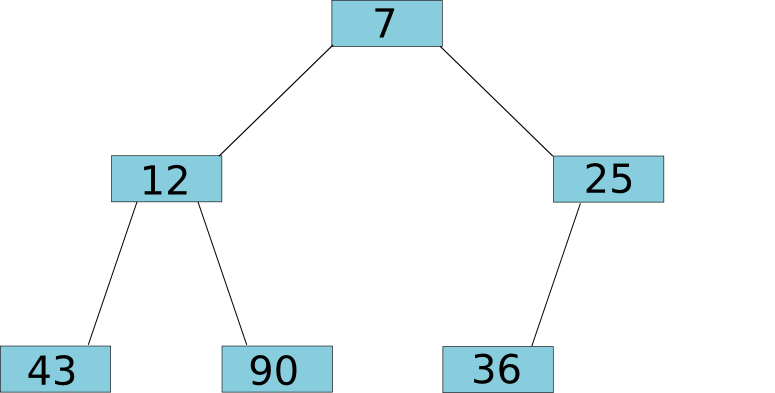
The key invariant is that the parent node of a tree is always lower than both of its children. The way to add a value to the tree is to add it to the end of the bottom level (or the start of a new bottom level if the current bottom level is full), and then to move the node up the tree, swapping it with its parents, for as long as the parent is higher than the child. At the end of the process, the invariant is again satisfied with the new node being in the tree at the right place:
To remove a node, we pop off the node at the top, take a node out from the bottom level and move it into its place, and then move that node down the tree as deep as makes sense:
And to see what the lowest node is, we, well, look at the top. The key point here is that both of these operations are logarithmic in the number of nodes in the tree; even if your heap has a billion items, it takes only 30 steps to add or remove a node. It’s a nontrivial exercise in computer science, but if you’re used to dealing with trees it’s not particularly complicated. Now, let’s try to implement this in Ethereum code. The full code sample for this is here; for those interested the parent directory also contains a batched market implementation using these heaps and an attempt at implementing futarchy using the markets. Here is a code sample for the part of the heap algorithm that handles adding new values:
# push if msg.data[0] == 0: sz = contract.storage[0] contract.storage[sz + 1] = msg.data[1] k = sz + 1 while k > 1: bottom = contract.storage[k] top = contract.storage[k/2] if bottom < top: contract.storage[k] = top contract.storage[k/2] = bottom k /= 2 else: k = 0 contract.storage[0] = sz + 1
The model that we use is that contract.storage[0] stores the size (ie. number of values) of the heap, contract.storage[1] is the root node, and from there for any n <= contract.storage[0], contract.storage[n] is a node with parent contract.storage[n/2] and children contract.storage[n*2] and contract.storage[n*2+1] (if n*2 and n*2+1 are less than or equal to the heap size, of course). Relatively simple.
Now, what’s the problem? In short, as we already mentioned, the primary concern is inefficiency. Theoretically, all tree-based algorithms have most of their operations take log(n) time. Here, however, the problem is that what we actually have is a tree (the heap) on top of a tree (the Ethereum Patricia tree storing the state) on top of a tree (leveldb). Hence, the market designed here actually has log3(n) overhead in practice, a rather substantial slowdown.
As another example, over the last several days I have written, profiled and tested Serpent code for elliptic curve signature verification. The code is basically a fairly simple port of pybitcointools, albeit some uses of recursion have been replaced with loops in order to increase efficiency. Even still, the gas cost is staggering: an average of about 340000 for one signature verification.
And this, mind you, is after adding some optimizations. For example, see the code for taking modular exponents:
with b = msg.data[0]: with e = msg.data[1]: with m = msg.data[2]: with o = 1: with bit = 2 ^ 255: while gt(bit, 0): # A touch of loop unrolling for 20% efficiency gain o = mulmod(mulmod(o, o, m), b ^ !(!(e & bit)), m) o = mulmod(mulmod(o, o, m), b ^ !(!(e & div(bit, 2))), m) o = mulmod(mulmod(o, o, m), b ^ !(!(e & div(bit, 4))), m) o = mulmod(mulmod(o, o, m), b ^ !(!(e & div(bit, 8))), m) bit = div(bit, 16) return(o)
This takes up 5084 gas for any input. It is still a fairly simple algorithm; a more advanced implementation may be able to speed this up by up to 50%, but even still iterating over 256 bits is expensive no matter what you do.
What these two examples show is that high-performance, high-volume decentralized applications are in some cases going to be quite difficult to write on top of Ethereum without either complex instructions to implement heaps, signature verification, etc in the protocol, or something to replace them. The mechanism that we are now working on is an attempt conceived by our lead developer Gavin Wood to essentially get the best of both worlds, preserving the generality of simple instructions but at the same time getting the speed of natively implemented operations: native code extensions.
Native Code Extensions
The way that native code extensions work is as follows. Suppose that there exists some operation or data structure that we want Ethereum contracts to have access to, but which we can optimize by writing an implementation in C++ or machine code. What we do is we first write an implementation in Ethereum virtual machine code, test it and make sure it works, and publish that implementation as a contract. We then either write or find an implementation that handles this task natively, and add a line of code to the message execution engine which looks for calls to the contract that we created, and instead of sub-calling the virtual machine calls the native extension instead. Hence, instead of it taking 22 seconds to run the elliptic curve recovery operation, it would take only 0.02 seconds.
The problem is, how do we make sure that the fees on these native extensions are not prohibitive? This is where it gets tricky. First, let’s make a few simplifications, and see where the economic analysis leads. Suppose that miners have access to a magic oracle that tells them the maximum amount of time that a given contract can take. Without native extensions, this magic oracle exists now – it consists simply of looking at the STARTGAS of the transaction – but it becomes not quite so simple when you have a contract whose STARTGAS is 1000000 and which looks like it may or may not call a few native extensions to speed things up drastically. But suppose that it exists.
Now, suppose that a user comes in with a transaction spending 1500 gas on miscellaneous business logic and 340000 gas on an optimized elliptic curve operation, which actually costs only the equivalent of 500 gas of normal execution to compute. Suppose that the standard market-rate transaction fee is 1 szabo (ie. micro-ether) per gas. The user sets a GASPRICE of 0.01 szabo, effectively paying for 3415 gas, because he would be unwilling to pay for the entire 341500 gas for the transaction but he knows that miners can process his transaction for 2000 gas’ worth of effort. The user sends the transaction, and a miner receives it. Now, there are going to be two cases:
- The miner has enough unconfirmed transactions in its mempool and is willing to expend the processing power to produce a block where the total gas used brushes against the block-level gas limit (this, to remind you, is 1.2 times the long-term exponential moving average of the gas used in recent blocks). In this case, the miner has a static amount of gas to fill up, so it wants the highest GASPRICE it can get, so the transaction paying 0.01 szabo per gas instead of the market rate of 1 szabo per gas gets unceremoniously discarded.
- Either not enough unconfirmed transactions exist, or the miner is small and not willing or able to process every transaction. In this case, the dominating factor in whether or not a transaction is accepted is the ratio of reward to processing time. Hence, the miner’s incentives are perfectly aligned, and since this transaction has a 70% better reward to cost rate than most others it will be accepted.
What we see is that, given our magic oracle, such transactions will be accepted, but they will take a couple of extra blocks to get into the network. Over time, the block-level gas limit would rise as more contract extensions are used, allowing the use of even more of them. The primary worry is that if such mechanisms become too prevalent, and the average block’s gas consumption would be more than 99% native extensions, then the regulatory mechanism preventing large miners from creating extremely large blocks as a denial-of-service attack on the network would be weakened – at a gas limit of 1000000000, a malicious miner could make an unoptimized contract that takes up that many computational steps, and freeze the network.
So altogether we have two problems. One is the theoretical problem of the gaslimit becoming a weaker safeguard, and the other is the fact that we don’t have a magic oracle. Fortunately, we can solve the second problem, and in doing so at the same time limit the effect of the first problem. The naive solution is simple: instead of GASPRICE being just one value, there would be one default GASPRICE and then a list of [address, gasprice] pairs for specific contracts. As soon as execution enters an eligible contract, the virtual machine would keep track of how much gas it used within that scope, and then appropriately refund the transaction sender at the end. To prevent gas counts from getting too out of hand, the secondary gas prices would be required to be at least 1% (or some other fraction) of the original gasprice. The problem is that this mechanism is space-inefficient, taking up about 25 extra bytes per contract. A possible fix is to allow people to register tables on the blockchain, and then simply refer to which fee table they wish to use. In any case, the exact mechanism is not finalized; hence, native extensions may end up waiting until PoC7.
Mining
The other change that will likely begin to be introduced in PoC7 is a new mining algorithm. We (well, primarily Vlad Zamfir) have been slowly working on the mining algorithm in our mining repo, to the point where there is a working proof of concept, albeit more research is required to continue to improve its ASIC resistance. The basic idea behind the algorithm is essentially to randomly generate a new circuit every 1000 nonces; a device capable of processing this algorithm would need to be capable of processing all circuits that could be generated, and theoretically there should exist some circuit that conceivably could be generated by our system that would be equivalent to SHA256, or BLAKE, or Keccak, or any other algorithms in X11. Hence, such a device would have to be a generalized computer – essentially, the aim is something that tried to approach mathematically provable specialization-resistance. In order to make sure that all hash functions generated are secure, a SHA3 is always applied at the end.
Of course, perfect specialization-resistance is impossible; there will always be some features of a CPU that will prove to be extraneous in such an algorithm, so a nonzero theoretical ASIC speedup is inevitable. Currently, the biggest threat to our approach is likely some kind of rapidly switching FPGA. However, there is an economic argument which shows that CPUs will survive even if ASICs have a speedup, as long as that speedup is low enough; see my earlier article on mining for an overview of some of the details. A possible tradeoff that we will have to make is whether or not to make the algorithm memory-hard; ASIC resistance is hard enough as it stands, and memory-hardness may or may not end up interfering with that goal (cf. Peter Todd’s arguments that memory-based algorithms may actually encourage centralization); if the algorithm is not memory-hard, then it may end up being GPU-friendly. At the same time, we are looking into hybrid-proof-of-stake scoring functions as a way of augmenting PoW with further security, requiring 51% attacks to simultaneously have a large economic component.
With the protocol in an increasingly stable state, another area in which it is time to start developing is what we are starting to call “Ethereum 1.5” – mechanisms on top of Ethereum as it stands today, without the need for any new adjustments to the core protocol, that allow for increased scalability and efficiency for contracts and decentralized applications, either by cleverly combining and batching transactions or by using the blockchain only as a backup enforcement mechanism with only the nodes that care about a particular contract running that contract by default. There are a number of mechanism in this category; this is something that will see considerably increased attention from both ourselves and hopefully others in the community.
[ad_2]
Source link


 Bitcoin
Bitcoin  Tether
Tether  XRP
XRP  USDC
USDC  Dogecoin
Dogecoin  LEO Token
LEO Token {kind=link}