
[ad_1]
After waaay too much time under development, we’re proud to finally announce version 1.8.0 of the Go Ethereum client: Iceberg! The release fixes a lot of pain points felt by the community and ships a few notable new features, tallying up to ~170 modifications!
Please note, this release introduces a few breaking changes that may affect certain power users! If you are running a production setup, make sure you read the “Breaking changes” section at the end of this blog post!
Client synchronization
A huge amount of work went into this release that isn’t immediately visible, rather they’re under the hood changes to make everybody’s life just a little bit more pleasant. We’ve tried to address many of the issues our users were reporting around syncing and block processing. We’re not quite where we’d like to be, but the experience with v1.8.0 should blow all previous releases out of the water.
Reliable light client
Geth v1.7.3 – released shortly after Devcon3 – was the first release to ship version 2 of the light client protocol. It was meant to be a huge improvement over version 1, finally enabling log filtering from Ethereum contracts. It broke the light client.
The breakage was massive, with multiple experimental protocols (discovery v5, light client v2) playing badly with each other. Geth v1.7.3 tried to advertise both les/1 and les/2, which conflicted in the discovery, breaking both; les/2 servers would crash serving some light client requests; and discovery v5, running behind an undocumented port, didn’t help either.
Geth v1.8.0 tries to pick up all the pieces and make les/2 what it was supposed to be in v1.7.3. We’ve dropped support for les/1 in the discovery, so there should be no more problems finding peers while we iron out the kinks. Light servers have been polished up to be more robust with existing connections, as well as extended to cleanly separate eth and les peers, preventing server side starvation. Version 4 and 5 of the discovery protocols are also running on the same port, and will from now on better avoid issues with firewalls or NAT traversals.
With all of the above changes, the light client in v1.8.0 should find servers within a few seconds from startup, and synchronizing the mainnet should finish within a minute. Since light clients rely on charitable nodes serving them, we ask anyone running non-sensitive full nodes with spare capacity to consider enabling the light server to help people with less capable hardware.
Reliable fast sync
For a long time now we’ve been receiving reports from users experiencing fast sync hangs with a “stalling peer” error message, or that trying to synchronize on an average machine often crashes with an “out of memory” error. These issues have become more and more prevalent as the Ethereum mainnet grew, yet they have been elusive to us due to their rare occurrence.
The heavy internal rewrites allowed us to reliably reproduce and fix these issues. The hang was a very rare race that occurred when state sync restarted; the fix for which is amusing given that it took us a year to catch. The memory issue was also fixed by aggressively capping the amount of memory that sync may consume.
The final result of these optimizations is that fast sync became stable again. From one perspective there are no more hangs, so you don’t have to constantly monitor the sync progress. From the other perspective memory usage is constant, so there’s no need for machines with insane RAM.
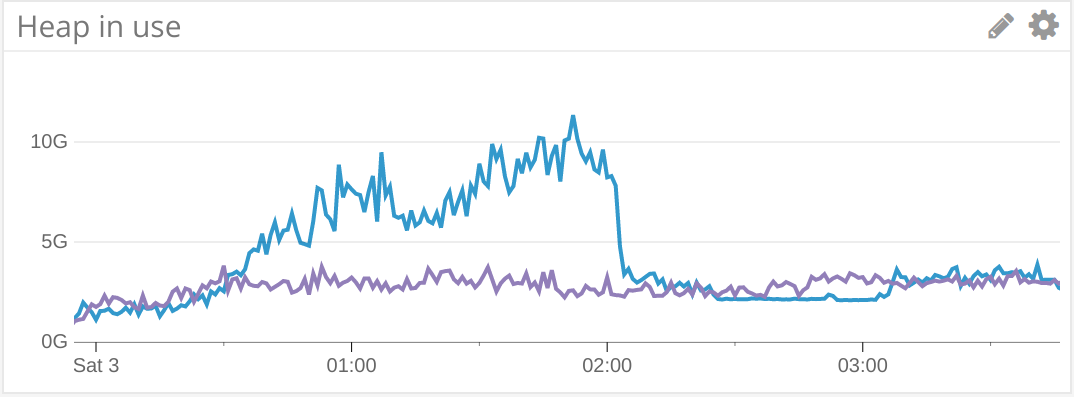
The above chart plots the memory usage during mainnet fast sync of two m4.2xlarge Amazon instance types (purple = Geth 1.8, blue = Geth 1.7). At the time of writing, fast sync completes in around 3 hours on these instance types. The exponential growth of Ethereum however resulted in a state trie of around 85 million nodes, the import of which can take even half a day on end-user laptops (with an SSD). Hopefully 1.9 will tackle this issue.
Initial state pruning
Ethereum organizes its state into a gigantic trie data structure. At the bottom – in the leaves we have the accounts – and on top of the accounts we have an 16th order Merkle trie cryptographically guaranteeing forgery resistance. We have one of these giant tries for each and every block, the latest of which weighing at around 85 million nodes. Most of these nodes are common between subsequent blocks, but every new block does add a few thousand new nodes into the trie.
If we would like to know what our balance was years ago, we’d have to maintain every single version of this Merkle trie since the genesis block, which could total to almost 1TB of data currently. In reality almost nobody cares about historical data – as long as it can be recomputed – rather only about the recent state of the network. Fast sync gets you “quickly” to the recent state, but blindly piling blocks on top will forever use more and more disk space.
The important property of the Merkle tries to be aware of is that whilst every new block adds thousands of new nodes, thousands of old ones become obsolete at the same time. If we could easily delete these obsolete ones, disk growth would be significantly capped. However, once the data is on disk, it’s extremely expensive to get rid of them.
Geth v1.8.0 takes an initial stab at the problem by introducing an in-memory cache in which to store the recent trie nodes. As long as the nodes are in memory, they are cheap to reference count and garbage collect. Instead of writing each trie node to disk, we keep it around as long as possible, hoping that a future block will make it obsolete and save us a database write.
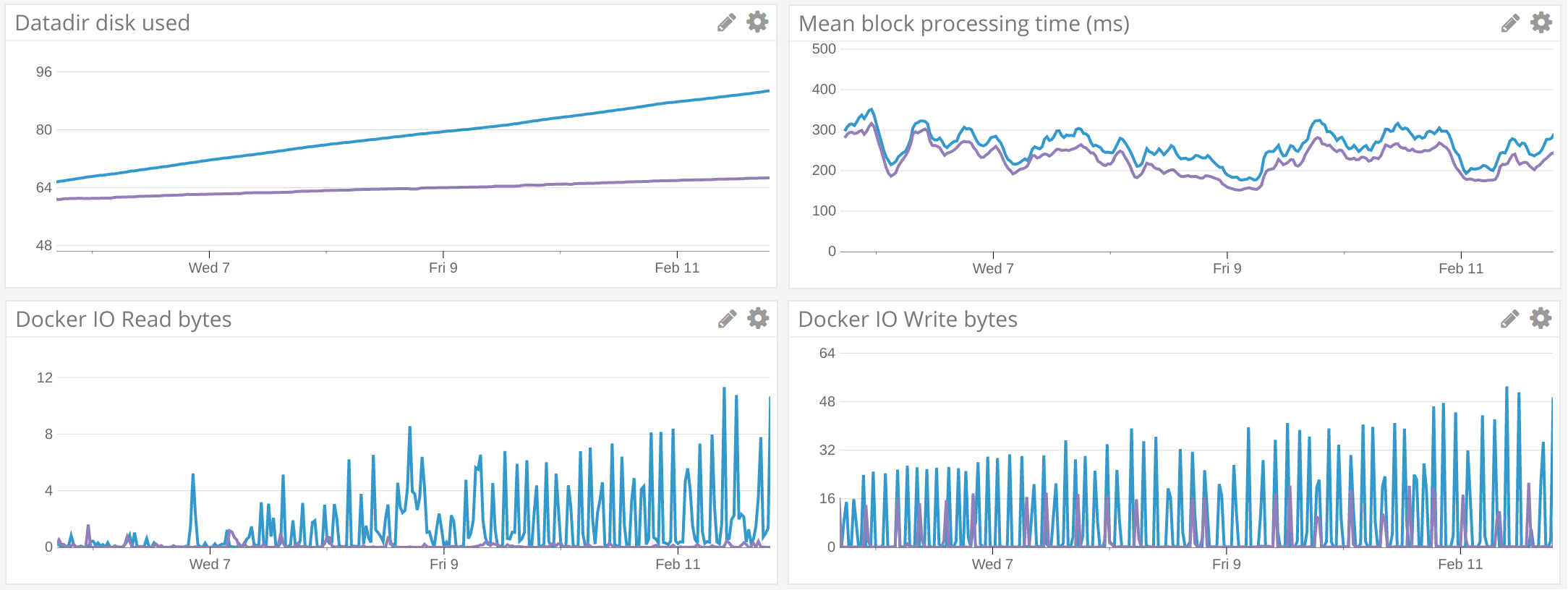
Geth v1.8.0 by default will use 25% of the user’s cache allowance (–cache) for trie caching and will flush to disk either if the memory allowance is exceeded, or if block processing time since the last flush exceeds 5 minutes. This doesn’t completely solve database growth just yet, but looking at the disk stats between v1.8 (purple) and v1.7 (blue) in the course of a single week, pruning makes a huge difference.
Transaction tracing
Pretty much since forever, Geth supported tracing transactions by dumping the executed opcodes. These dumps can be invaluable for finding consensus issues among clients, but they aren’t the nicest to look at. Although post-processing these traces is possible, it’s a waste of resources to collect so much data just to throw most of it away.
Custom tracing scripts
The v1.5 release family of Geth introduced a new way to trace transactions by allowing users to write custom JavaScript scripts that run within the node while tracing. Instead of producing pre-defined traces, users could gather whatever data they deemed useful without having to export everything else. Although we did use it internally, the feature never really graduated to a useful and robust enough state for wide spread use.
Geth v1.8.0 however completely revamps the custom tracing support. For starters, we’ve replaced the ottovm we used previously to run the tracers, to duktape, resulting in a 5x speed increase. We no longer require the state upon which a transaction relies to be present to trace it, rather the tracer can reconstruct anything missing from historical states (bearing the cost of re-executing the blocks in memory). Furthermore, when tracing multiple transactions at once (i.e. an entire block), those are executed concurrently, slashing tracing time by the number of available CPU cores.
All said and done, writing a custom tracer is complicated, taking up a significant time even for veteran Ethereum developers. As such, we’ve made the decision to provide a few tracers out of the box for users to use, and potentially improve. We eagerly await any community improvements to these, or even the addition of brand new ones!
- The callTracer is a full blown transaction tracer that extracts and reports all the internal calls made by a transaction, along with any information deemed useful.
- The prestateTracer outputs sufficient information to create a local execution of the transaction from a custom assembled genesis block.
- The 4byteTracer searches for 4byte-identifiers, and collects them for post-processing. It collects the methods identifiers along with the size of the supplied data, so a reversed signature can be matched against the size of the data.
E.g. executing the callTracer against the same transaction linked above gets us a much much friendlier output debug.traceTransaction(“0xhash”, {tracer: “callTracer”}).

Streaming chain tracers
Tracing an entire block of transactions is a lot more optimal than tracing transactions one-by-one, because we don’t need to generate the pre-state for each one individually. This holds true even more strongly if generating the starting state entails re-executing multiple past blocks (pruned state). The same issue however arises when tracing multiple blocks too: if the pre-state was pruned, it’s a waste to throw away regenerated state just to do it all over for the next block.
To cater for tracing multiple subsequent blocks with minimal overhead, Geth v1.8.0 introduces a new API endpoint that can trace chain segments. This endpoint can reuse the computed states in between blocks without rerunning transactions over and over again. What’s more, individual blocks are traced concurrently, so total tracing time gets proportionally lower the more CPU cores you throw at it.
Tracing a transaction or a block takes a relatively short amount of time. Tracing a chain segment however can take arbitrarily long, depending on how long the chain is and what transactions are included in it. It would be very impractical to wait for all the transactions to be traced before starting to return the ones already done. This rules out chain tracing as a simple RPC method. Instead, Geth v1.8.0 implements chain tracing via a subscription (IPC/WebSocket), where the user starts a background tracing process and Geth will stream the results until all transactions are traced:
$ nc -U /work/temp/rinkeby/geth.ipc {"id": 1, "method": "debug_subscribe", "params": ["traceChain", "0x0", "0xfff", {"tracer": "callTracer"}]}
{"jsonrpc":"2.0","id":1,"result":"0xe1deecc4b399e5fd2b2a8abbbc4624e2"} {"jsonrpc":"2.0","method":"debug_subscription","params":{"subscription":"0xe1deecc4b399e5fd2b2a8abbbc4624e2","result":{"block":"0x37","hash":"0xdb16f0d4465f2fd79f10ba539b169404a3e026db1be082e7fd6071b4c5f37db7","traces":[{"from":"0x31b98d14007bdee637298086988a0bbd31184523","gas":"0x0","gasUsed":"0x0","input":"0x","output":"0x","time":"1.077µs","to":"0x2ed530faddb7349c1efdbf4410db2de835a004e4","type":"CALL","value":"0xde0b6b3a7640000"}]}}} {"jsonrpc":"2.0","method":"debug_subscription","params":{"subscription":"0xe1deecc4b399e5fd2b2a8abbbc4624e2","result":{"block":"0xf43","hash":"0xacb74aa08838896ad60319bce6e07c92edb2f5253080eb3883549ed8f57ea679","traces":[{"from":"0x31b98d14007bdee637298086988a0bbd31184523","gas":"0x0","gasUsed":"0x0","input":"0x","output":"0x","time":"1.568µs","to":"0xbedcf417ff2752d996d2ade98b97a6f0bef4beb9","type":"CALL","value":"0xde0b6b3a7640000"}]}}} {"jsonrpc":"2.0","method":"debug_subscription","params":{"subscription":"0xe1deecc4b399e5fd2b2a8abbbc4624e2","result":{"block":"0xf47","hash":"0xea841221179e37ca9cc23424b64201d8805df327c3296a513e9f1fe6faa5ffb3","traces":[{"from":"0xbedcf417ff2752d996d2ade98b97a6f0bef4beb9","gas":"0x4687a0","gasUsed":"0x12e0d","input":"0x6060604052341561000c57fe5b5b6101828061001c6000396000f30060606040526000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff168063230925601461003b575bfe5b341561004357fe5b61008360048080356000191690602001909190803560ff1690602001909190803560001916906020019091908035600019169060200190919050506100c5565b604051808273ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16815260200191505060405180910390f35b6000600185858585604051806000526020016040526000604051602001526040518085600019166000191681526020018460ff1660ff1681526020018360001916600019168152602001826000191660001916815260200194505050505060206040516020810390808403906000866161da5a03f1151561014257fe5b50506020604051035190505b9493505050505600a165627a7a7230582054abc8e7b2d8ea0972823aa9f0df23ecb80ca0b58be9f31b7348d411aaf585be0029","output":"0x60606040526000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff168063230925601461003b575bfe5b341561004357fe5b61008360048080356000191690602001909190803560ff1690602001909190803560001916906020019091908035600019169060200190919050506100c5565b604051808273ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16815260200191505060405180910390f35b6000600185858585604051806000526020016040526000604051602001526040518085600019166000191681526020018460ff1660ff1681526020018360001916600019168152602001826000191660001916815260200194505050505060206040516020810390808403906000866161da5a03f1151561014257fe5b50506020604051035190505b9493505050505600a165627a7a7230582054abc8e7b2d8ea0972823aa9f0df23ecb80ca0b58be9f31b7348d411aaf585be0029","time":"658.529µs","to":"0x5481c0fe170641bd2e0ff7f04161871829c1902d","type":"CREATE","value":"0x0"}]}}} {"jsonrpc":"2.0","method":"debug_subscription","params":{"subscription":"0xe1deecc4b399e5fd2b2a8abbbc4624e2","result":{"block":"0xfff","hash":"0x254ccbc40eeeb183d8da11cf4908529f45d813ef8eefd0fbf8a024317561ac6b"}}}
Native events
For about one and a half years now we’ve supported generating Go wrappers for Ethereum contracts. These are extremely useful as they allow calling and transacting with contracts directly using Go. The main benefit is that our abigen tool generates static types for just about everything, ensuring that code interacting with contracts is compile-time type safe. It’s very useful during development too, as any contract ABI change immediately produces compilation errors, eliminating most runtime failures.
That being said, abigen was always lacking support for Ethereum contract log filtering: you couldn’t filter past events, and you couldn’t subscribe to future events. Geth v1.8.0 finally lands event filtering for native dapps! Go wrappers generated by abigen from now on will contain two extra methods for each event, FilterMyEvent and WatchMyEvent. Adhering to abigen‘s strict type safety, both event filters and returned logs are strongly and statically typed. Developers only need to work with Go types, and everything else gets taken care of under the hood.
A nice example is filtering for Akasha posts on the Rinkeby test network. The publishing event is defined as event Publish(address indexed author, bytes32 indexed entryId). Filtering for posts created by addresses 0xAlice or 0xBob would look like:
contract.FilterPublish(nil, []common.Address{"0xAlice", "0xBob"}, nil)
Devcon3 puppeth
As many of you probably know, the Rinkeby test network is almost fully managed via puppeth. For those who don’t, puppeth is “a tool to aid you in creating a new Ethereum network down to the genesis block, bootnodes, signers, ethstats server, crypto faucet, wallet browsers, block explorer, dashboard and more; without the hassle that it would normally entail to manually configure all these services one by one”.
Puppeth was an invaluable tool for us in maintaining the Rinkeby network since its creation 10 months ago. It was fit for its purpose – as an internal tool – alas it had a lot of rough edges. We wanted to make this tool useful not just for Rinkeby, rather for all other developer networks out there too, so for Devcon3 we’ve heavily polished it. It became user friendly(-er), it gained support for configuring Parity, C++ Ethereum, pyethapp and Harmony (on ethash consensus) and it could deploy online wallets and basic block explorers too.
It seems to have been ages since Devcon3 and Puppeth being merged on master, but v1.8.0 finally ships the next incarnation of puppeth for those who have been holding out. Go on and deploy your own Ethereum network!
Breaking changes
- Discovery v4 and v5 have been merged to use the same UDP port (30303 by default). If you are doing manual peer management and using the light client, you may need to ensure your v1.8.0 clients are pointed to port 30303 and not 30304 as previously.
- Trie pruning is enabled on all –syncmode variations (including –syncmode=full). If you are running an archive node where you would like to retain all historical data, you should disable pruning via –gcmode=archive.
- Only the latest 128 tries are kept in memory, most tries are garbage collected. If you are running a block explorer or other service relying on transaction tracing without an archive node (–gcmode=archive), you need to trace within this window! Alternatively, specify the reexec: 12345 tracer option to allow regenerating historical state; and ideally switch to chain tracing which amortizes overhead across all traced blocks.
- Native events rely on modifications to internal go-ethereum types within generated code. If you are using wrappers generated prior to v1.8.0, you will need to regenerate them to be compatible with the new code base.
- The HTTP/WS RPC endpoint was extended with DNS rebind protection. If you are running an RPC endpoint addressed by name rather than IP, run with –rpcvhosts=your.domain to continue accepting remote requests.
Although we consider Geth 1.8.0 our best release yet, we urge everyone to exercise caution with the upgrade and monitor it closely afterwards as it does contain non-trivial changes. We would also like to emphasize that Geth 1.8.0 introduces state pruning, which is backward incompatible with previous versions of Geth (old versions reject the pruned database).
As with previous large releases, our recommendation for production users it to sync from scratch, and leave the old database backed up until you confirm that the new release works correctly for all your use cases.
For a full rundown of the changes please consult the Geth 1.8.0 release milestone.
Binaries and mobile libraries are available on our download page.
Acknowledgement
As a final note for this release, we’d like to shout out to Ming Chan for all of her insanely hard work as the previous EF Executive Director! Among her multitude of tasks, she always found the time to proof-read our release posts, correcting any lost-in-translation errors; whilst also ensuring clarity for our less technical readers. Thank you for everything you did for the Foundation and the community!
¹ “Because the previous version was un-sync-able” ~Nick Johnson
[ad_2]
Source link




 Bitcoin
Bitcoin  Tether
Tether  XRP
XRP  USDC
USDC  Dogecoin
Dogecoin  LEO Token
LEO Token {kind=link}
{kind=link}
{kind=link}