
[ad_1]
After many months of silence, we’re proud to announce the v1.9.0 release of Go Ethereum! Although this release has been in the making for a lot longer than we anticipated, we’re confident there will be some juicy feature for everyone to enjoy!
Warning: We’ve tried our best to squash all the bugs, but as with all major releases, we advise everyone to take extra care when upgrading. The v1.9.0 release contains database schema changes, meaning it’s not possible to downgrade once updated. We also recommend a fresh fast sync as it can drastically reduce the database size.
Some of the features mentioned here have been silently shipped over the course of the 1.8.x release family, but we’ve deemed them important enough to explicitly highlight.
Performance
It’s interesting to realize that the “Performance” section was somewhere at the end of previous announcements, but over the years it became one of the most sought after improvement.
Over the past 6 months, we’ve tried to dissect the different components that are on the critical path of block processing, in an attempt to identify and optimize some of bottlenecks. Among the many improvements, the highest impact ones were:
- The discovery and optimization of a quadratic CPU and disk IO complexity, originating from the Go implementation of LevelDB. This caused Geth to be starved and stalled, exponentially getting worse as the database grew. Huge shoutout to Gary Rong for his relentless efforts, especially as his work is beneficial to the entire Go community.
- The analysis and optimization of the account and storage trie access patterns across blocks. This resulted in stabilizing Geth’s memory usage even during the import of the Shanghai DoS blocks and speeding up overall block processing by concurrent heuristic state prefetching. This work was mostly done by Péter Szilágyi.
- The analysis and optimization of various EVM opcodes, aiming to find outliers both in Geth’s EVM implementation as well as Ethereum’s protocol design in general. This led to both fixes in Geth as well as infos funneled into the Eth 1.x scaling discussions. Shoutout goes to Martin Holst Swende for pioneering this effort.
- The analysis and optimization of our database schemas, trying to both remove any redundant data as well as redesign indexes for lower disk use (sometimes at the cost of a slight CPU hit). Props for these efforts (spanning 6-9 months) go to Alexey Akhunov, Gary Rong, Péter Szilágyi and Matthew Halpern.
- The discovery of a LevelDB compaction overhead during the state sync phase of fast sync. By temporarily allocating pruning caches to fast sync blooms, we’ve been able to short circuit most data accesses in-memory. This work was mostly done by Péter Szilágyi.
[TL;DR] Fast sync
We’ve run a fast sync benchmark on two i3.2xlarge AWS EC2 instances (8 core, 61 GiB RAM, 1.9 TiB NVMe SSD) with –cache=4096 –maxpeers=50 (defaults on v1.9.0) on the 25th of April.
| Version | Sync time | Disk size | Disk reads | Disk writes |
|---|---|---|---|---|
| Geth v1.8.27 | 11h 20m | 176GiB | 1.58TiB | 1.94TiB |
| Geth v1.9.0 | 4h 8m | 131GiB | 0.91TiB | 1.06TiB |
[TL;DR] Full sync
We’ve run a full sync benchmark on two i3.2xlarge AWS EC2 instances (8 core, 61 GiB RAM, 1.9 TiB NVMe SSD) with –cache=4096 –maxpeers=50 –syncmode=full.
| Version | Sync time | Disk size | Disk reads | Disk writes |
|---|---|---|---|---|
| Geth v1.8.27 | 6d 15h 30m | 341GiB | 28.9TiB | 21.8TiB |
| Geth v1.9.0 | 6d 8h 7m* | 303GiB | 40.2TiB* | 32.6TiB* |
*Whilst the performance is similar, we’ve achieved that while reducing the memory use by about 1/3rd and completely removing spurious memory peaks (Shanghai DoS). The reason for the higher disk IO is due to using less memory for caching, having to push more aggressively to disk.
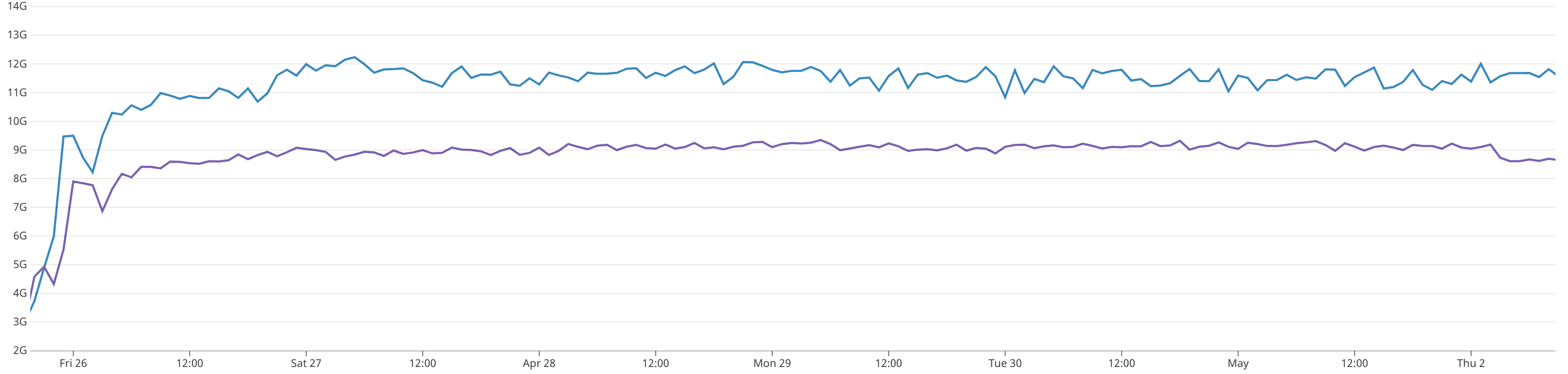
[TL;DR] Archive sync
We’ve run an archive sync benchmark on two m5.2xlarge AWS EC2 instances (8 core, 32 GiB RAM, 3TiB EBS SSD) with –cache=4096 –syncmode=full –gcmode=archive.
| Version | Sync time | Disk size | Disk reads | Disk writes |
|---|---|---|---|---|
| Geth v1.8.27 | 62d 4h | 2.57TiB | 69.29TiB | 49.03TiB |
| Geth v1.9.0 | 13d 19h* | 2.32TiB | 104.73TiB | 91.4TiB |
* EBS volumes are significantly slower than physical SSDs attached to the VM. Better performance can be achieved on VMs with real SSDs or actual physical hardware.
Freezer
Wouldn’t it be amazing if we didn’t have to waste so much precious space on our expensive and sensitive SSDs to run an Ethereum node, and could rather move at least some of the data onto a cheap and durable HDD?
With the v1.9.0 release, Geth separated its database into two parts (done by Péter Szilágyi, Martin Holst Swende and Gary Rong):
- Recent blocks, all state and accelerations structures are kept in a fast key-value store (LevelDB) as until now. This is meant to be run on top of an SSD as both disk IO performance is crucial.
- Blocks and receipts that are older than a cutoff threshold (3 epochs) are moved out of LevelDB into a custom freezer database, that is backed by a handful of append-only flat files. Since the node rarely needs to read these data, and only ever appends to them, an HDD should be more than suitable to cover it.
A fresh fast sync at block 7.77M placed 79GB of data into the freezer and 60GB of data into LevelDB.
Freezer basics
By default Geth will place your freezer inside your chaindata folder, into the ancient subfolder. The reason for using a sub-folder was to avoid breaking any automated tooling that might be moving the database around or across instances. You can explicitly place the freezer in a different location via the –datadir.ancient CLI flag.
When you update to v1.9.0 from an older version, Geth will automatically being migrating blocks and receipts from the LevelDB database into the freezer. If you haven’t specified –datadir.ancient at that time, but would like to move it later, you will need to copy the existing ancient folder manually and then start Geth with –datadir.ancient set to the correct path.
Freezer tricks
Since the freezer (cold data) is stored separately from the state (hot data), an interesting question is what happens if one of the two databases goes missing?
- If the freezer is deleted (or a wrong path specified), you essentially pull the rug from underneath Geth. The node would become unusable, so it explicitly forbids doing this on startup.
- If, however, the state database is the one delete, Geth will reconstruct all its indices based on the frozen data; and then do a fast sync on top to back-fill the missing state.
Essentially, the freezer can be used as a guerrilla state pruner to periodically get rid of accumulated junk. By removing the state database, but not the freezer, the node will do a fast sync to fetch the latest state, but will reuse all the existing block and receipt data already downloaded previously.
You can trigger this via geth removedb (plus the –datadir and –datadir.ancient flags if you used custom ones); asking it to only remove the state database, but not the ancient database.
Be advised, that reindexing all the transactions from the ancient database can take over an hour, and fast sync will only commence afterwards. This will probably be changed into a background process in the near future.
GraphQL
Who doesn’t just love JSON-RPC? Me!
As its name suggests, JSON-RPC is a *Remote Procedure Call* protocol. Its design goal is to permit calling functions, that do some arbitrary computation on the remote side, after which they return the result of said computation. Of course – the protocol being generic – you can run data queries on top, but there’s no standardized query semantic, so people tend to roll their own.
Without support for flexible queries however, we end up wasting both computational and data transfer resources:
- RPC calls that return a lot of data (e.g. eth_getBlock) waste bandwidth if the user is only interested in a handful of fields (e.g. only the header, or even less, only the miner’s address).
- RPC calls that return only a bit of data (e.g. eth_getTransactionReceipt) waste CPU capacity if the user is forced to repeat the call multiple times (e.g. retrieving all receipts one-by-one results in loading all of them from disk for each call).
In the case of Ethereum’s JSON-RPC API, the above issues get exacerbated by the mini-reorg nature of the blockchain, as doing multiple queries (e.g. eth_getBalance) need to actually ensure that they execute against the same state and even against the same node (e.g. load balanced backends might have slight sync delays, so can serve different content).
Yes, we could invent a new, super optimal query mechanism that would permit us to retrieve only the data we need, whilst minimizing computational and data transfer overhead… or we could also not-reinvent the wheel (again) and rather use one that’s been proven already: GraphQL.
Querying with GraphQL
First thing’s first, a huge shoutout goes to Raúl Kripalani, Kris Shinn, Nick Johnson, Infura and Pegasys, for pioneering both the GraphQL spec and its implementation, as well as to Guillaume Ballet for doing the final integrations!
Geth v1.9.0 introduces native GraphQL query capabilities via the –graphql CLI flag. GraphQL itself being a protocol on top of HTTP, the same suite of sub-flags (restrictions, CORS and virtual hosts rules) are available as for HTTP RPC. But enough of this yada-yada, let’s see it!
For a quick spin, lets try and find all the ENS domain registrations on the Görli testnet! Start Geth v1.9.0 on Görli with GraphQL enabled (geth –goerli –graphql), wait until it syncs (should be 1-2 minutes tops) and point your browser to the… gasp… built in GraphQL explorer at http://localhost:8547!
To keep things simple, here’s a quick sample query that finds the ENS HashRegistered events and returns the address of the user doing the registration along with the block number and timestamp it was included in:
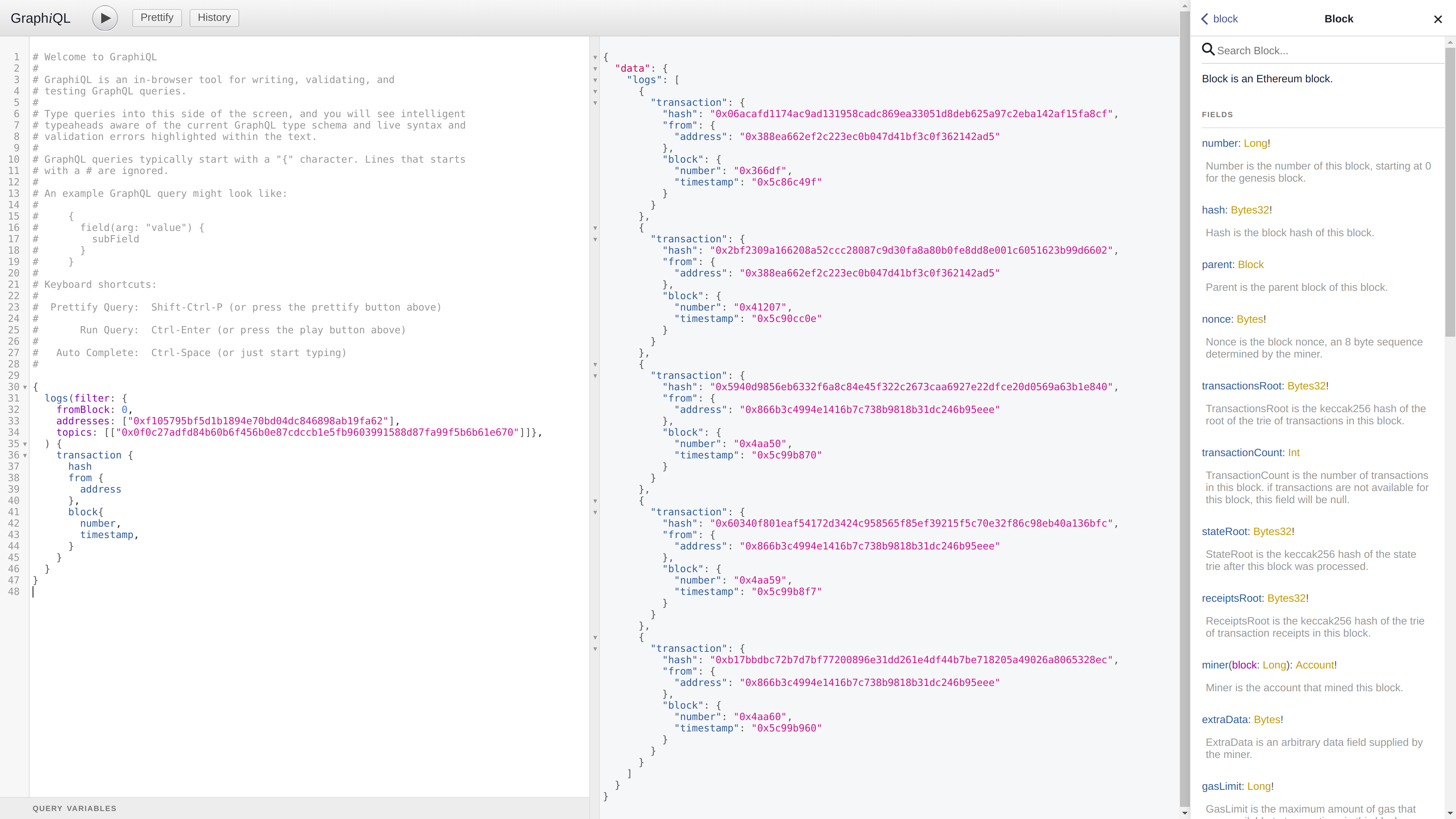
Albeit the example is a bit contrived and simplistic, it does highlight that GraphQL allows us to answer complex “join queries” that previously required many RPC calls and returned a lot more data than actually needed.
As with all epic developer tools, Geth v1.9.0’s GraphQL explorer has integrated code completion, field documentation and live query execution! Go and query something awesome!
Hardware wallets
Geth already supported certain hardware wallets in the past, but with the v1.9.0 release, we’ve upped our game and made that list a lot more extensive!

Ledger wallets
We’ve already supported the Ledger Nano S for a couple years now, but Geth v1.9.0 also introduces native support for the Ledger Nano X (via USB)!
Additionally, v1.9.0 replaces the default HD derivation path from the legacy one, that Ledger originally advertised, to the canonical one, used by all Ethereum wallets (and presently by Ledger too). Don’t worry, Geth will find all your old accounts too, just will use the canonical path for new accounts! This work was done by Péter Szilágyi.
If you haven’t used a Ledger through Geth until now, the workflow is:
- Plug in your Ledger Nano S or Ledger Nano X and unlock via your PIN code.
- Start the Ethereum app on your Ledger (Geth will log Ethereum app offline).
- You can list all your accounts via personal.listWallets from the Geth console.
- This will auto-derive any accounts that you’ve used before + 1 empty new one.
- Alternatively you can do the same thing through RPC via personal_listWallets.
- Transact via your preferred means and Geth will forward the signing request to the Ledger.
Linux users be aware, you need to explicitly permit your user to access your Ledger wallet via udev rules!
Trezor wallets
For almost two years now we’ve supported the Trezor One. Unfortunately a firmware update (v1.7.0+) changed the USB protocol in a backwards incompatible way. Although we recommend everyone use the latest software when it comes to security, we also acknowledge the reluctance of regularly updating firmware on a cold storage device.
As such, Geth v1.9.0 implements the new WebUSB protocol supporting updated Trezor One models, but at the same time keeps support for the old USB HID protocol too for non-updated devices. This support was added by Guillaume Ballet and Péter Szilágyi (we’ve even published a new usb library for Go to support it).
The Trezor One workflow is a bit more complex due to the unique PIN entry:
- Plug in your Trezor One, Geth will detect it but will prompt you to open it.
- Call personal.openWallet(‘trezor://…’) with the URL of the device.
- If you don’t know the URL, you can check via personal_listWallets.
- The console will keep prompting for PIN entry and password as needed.
- Calling via RPC, openWallet returns a detailed error if it needs another call.
- You can list all your accounts via personal.listWallets from the Geth console.
- This will auto-derive any accounts that you’ve used before + 1 empty new one.
- Alternatively you can do the same thing through RPC via personal_listWallets.
- Transact via your preferred means and Geth will forward the signing request to the Trezor.
In addition to extended support for the Trezor One, Geth v1.9.0 also introduces native support for the Trezor Model T. The Model T’s workflow is a bit simpler as the PIN entry is done on device:
- Plug in your Trezor Model T and unlock via your PIN code, Geth should detect it.
- You can list all your accounts via personal.listWallets from the Geth console.
- This will auto-derive any accounts that you’ve used before + 1 empty new one.
- Alternatively you can do the same thing through RPC via personal_listWallets.
- Transact via your preferred means and Geth will forward the signing request to the Trezor.
Linux users be aware, you need to explicitly permit your user to access your Trezor wallet via udev rules!
Status keycards
Prototyped more than a year ago, Geth v1.9.0 finally ships support for the Status keycard, a full HD hardware wallet based on Java SmartCards. The Status keycard can be used via Geth only through the PC/SC daemon for now (you need to install it) and via USB (the +iD is a good USB smartcard reader). This work was heavy lifted by Nick Johnson, initially integrated by Péter Szilágyi and finalized by Guillaume Ballet (and of course Andrea Franz and the rest of the Status team).
If you already have an initialized Status keycard, the Geth workflow is:
- Plug in your Status keycard via a USB card reader.
- Check the status of your card via personal_listWallets.
- Permit Geth to use the card via personal.openWallet(‘keycard://…’).
- The very first time Geth will ask you to pair your card via the passphrase.
- In normal operation, Geth will ask you to unlock your card via your PIN code.
- On too many wrong PINs, Geth will ask you to reset your card via your PUK code.
- On too many wrong PUKs, your card will be bricked and you’ll need to reinstall it.
- Alternatively you can do the same thing through RPC via multiple personal_openWallet().
- Transact via your preferred means and Geth will forward the signing request to the Status keycard.
If you don’t have a pre-initialized Status keycard; are using a developer card; or managed to brick your existing card (hey, we’re developers, we must know what happens then), you can follow our technical guide on how to wipe your keycard and reinitialize it. Note, you will lose your private key on a wipe.
Clef
Wallets, wallets everywhere!
When Ethereum launched in 2015, there was no third party tooling whatsoever, so client implementations needed to be these all-encompassing Swiss army knives. Ranging from peer-to-peer networking, through account management, to contract and user interactions, everything was done by the client. This was necessary, but seriously sub-optimal: accounts and networking don’t go well together security wise, and everything done by a single binary doesn’t permit a composable ecosystem.
We’ve been wanting to do this for at least 2 years now, and Geth v1.9.0 finally ships the work of Martin Holst Swende (with the help of many others): a standalone signer for the entire Ethereum ecosystem called Clef. As simple as a “standalone signer” might sound, Clef is the result of an insane amount of architectural work to make it secure, flexible and composable.
A small release blog post simply cannot do this project justice, but we’ll try nonetheless to at least mention the major features of Clef, the design decisions behind them and how they can enable a whole set of new use cases.
Ecosystem composability
The main reason for creating Clef was to remove account management from Geth (don’t worry, the old way will still work for the foreseeable future). This permits Geth to be an “insecure” network gateway into Ethereum, which should solve many many issues with regard to accidentally exposing accounts via RPC (and unlocking them, the deadly combo).
But hogging all this work for Geth wouldn’t be nice of us. Instead, we designed Clef to be usable by arbitrary programs, so that you can have a single signer securely managing your keys, to which arbitrary applications (e.g. Geth, Parity, Trinity, Metamask, MyCrypto, Augur) can send signing requests to!
To achieve this, Clef exposes a tiny external API (changelog) either via IPC (default) or HTTP. Any program that can access these endpoints (e.g. Geth via IPC, Metamask via HTTP) can send signing requests to Clef, which will prompt the user for manual confirmation. The API is deliberately tiny and uses JSON-RPC, so it should be trivial to support in any project.
Our goal with Clef is not to be “The Geth Signer”, rather we’d like it to become a standalone entity that can be used by any other project, be it different client implementations (Trinity), browser integrations (Metamask), service components (Raiden) or decentralized applications (Augur). If you’d like to integrate Clef, reach out and we’ll HEPL!
Pluggable interface
What is the perfect user interface?
If you ask me, I’d say command line: simple, works over SSH, and I can code it :D. But I’m a minority here and even I often prefer a proper UI. So, Electron? Some think it’s the best thing since sliced bread and many developers can code it; but it’s large and slow and JavaScript :P. How about Qt? It’s cross platform, tiny and fast, but not many developers are familiar with it and it has a funky license. Android, GTK, iThingy?… Win32 😂?
The answer is all of them! The perfect UI depends on what you want to use it for, and we don’t want to make that choice for you, rather allow you to run Clef the way it fits best into your life:
- If you are on the move all the time, you may prefer an Android or iOS interface.
- If you have a locked down remote server, you may prefer CLI on top of SSH.
- If you have a powerful laptop, the beauty of Electron might be just the thing.
- If you have an offline signer machine, a Qt UI might be simple, but enough.
- If you are a bank, you might want a custom integration into your own infra.
We can’t implement all this. But you can! We’ve designed Clef with enough flexibility to allow anyone to implement a custom UI on top, without needing to touch Clef itself, or know any Go at all. The goal is to provide a building block to the community so that designers and UI developers can do what they’re good at, without having to worry about cryptography and stuff.
To achieve this, Clef exposes an extended internal API (changelog), solely via standard input/output. Any user interface is meant to start itself up and internally start an instance of Clef, binding to it’s IO streams. The IO streams speak JSON-RPC, so the UI can send arbitrary trusted requests to Clef, and Clef will send notifications and confirmation prompts to the UI.
Clef itself ships with a built in CLI interface (otherwise it’s not much useful) and we’ve prepared an entire Quickstart Guide to familiarize yourself with the general features and concepts. There are also various proof-of-concept UIs that we’ve used to validate architectural decisions, but to get a solid UI, we need the community, as we don’t have the knowledge ourselves!
Integrated 4bytes
You probably figured out the general direction by now. We want Clef to be a reusable piece of puzzle. The trick is to make it the right size! Too much functionality baked in (e.g. fixed UI), and possible uses get limited. Too few (e.g. no hardware wallet) and UI builders reinvent the wheel. It’s a delicate balance of maximizing utility and security without compromising flexibility.
So, we agree that “fixed UI bad, pluggable UI good”, “no hardware wallet bad, Ledger + Trezor + Keycard good”. What else do wallet implementations reinvent all the time? 4bytes!
In Ethereum, whenever a user interacts with a contract, they send a giant blob of binary data, encoded in a very specific ABI format. This is needed so that the EVM can make heads or tails of it, and of course this is generated by some program (e.g. Augur). Problem is, the user is then prompted to confirm a transaction that looks like this:
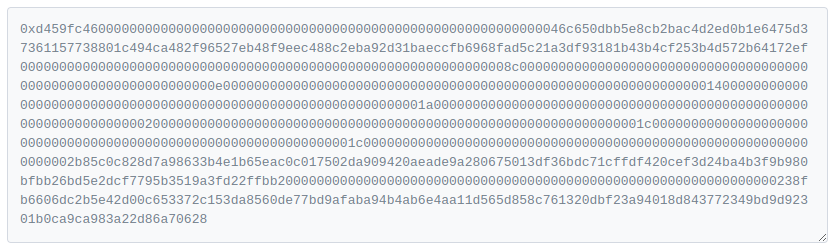
The solution of the Ethereum community was to assemble a 4byte database, so that by looking at the first 4 bytes of the above data, you can guess what the rest of the data is meant to represent, and can thus show the user a meaningful dump of what they are about to confirm (images above and below courtesy of Etherscan).
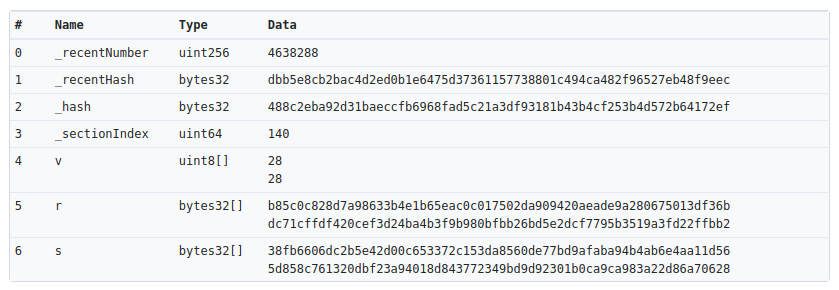
Currently all Ethereum wallet UIs reinvent the wheel when it comes to integrating 4bytes! The database is public, but the integrations are custom. Clef ships the entire 4byte database embedded in itself, and whenever a transaction is made, it decodes the calldata internally. Not only does Clef send the decoded call to the UI, but also adds warning messages if the data does not match the method signature! Clef will handle Ethereum, you can focus on the UI!
Programmatic rules
Clef seems awesome, what more could we ask for? Well… based on the above sections, we can build the perfect signer to confirm any and all of our transactions… manually. What happens, however, if we want to automate some of that (e.g. Clique signer, Raiden relay, Swarm exchange, etc). We could just not care and let the UI sort it out… but then we’re back in square one, as all wrapping UIs need to reinvent the same mechanisms, and most will probably do it insecurely.
Clef solves this via an encrypted key-value store and an ingenious rule engine! Instead of prompting the user to confirm each and every request via a passphrase entry, we can permit Clef to sign on our behalf by storing our passphrase in its encrypted database. This will only allow passwordless signing, but still needs manual confirmation!
As a second step, however, we can also provide Clef with a JavaScript rule file, that will run whenever a request arrives and can decide to auto-confirm, auto-reject, or forward the request for manual confirmation. The JavaScript rules have access to the entire request and can also store arbitrary data in a key-value store for persistence. E.g. An academic demo rule file:
function ApproveSignData(req) { if (req.address.toLowerCase() == '0xd9c9cd5f6779558b6e0ed4e6acf6b1947e7fa1f3') { if (req.messages[0].value.indexOf('bazonk') >= 0) { return 'Approve'; } return 'Reject'; } // Otherwise goes to manual processing }
The goal of these rules is to allow you to configure arbitrary approval logic for whatever your use case might be, whether that’s automatic server-side transactions (Clique, Raiden, Swarm, Faucet) or low-value client-side automation (approve X Wei / 24h to Augur). The programmable rules ensure that Clef remains true to its composability promise, permitting anyone to build their dream integration on top.
For a full demo on how to set up automatic rules, please check the Clef Quickstart Guide.
Light clients
Light clients are tricky and they make everything more complicated than it should be. The root cause is more philosophical than technical: the best things in life are free, and the second best are cheap. In Ethereum client terms, the “best” clients are those that work with 0 overhead (think Metamask, Infura), the second best are the light clients.
Problem is, trusted servers go against the ethos of the project, but light clients are often too heavy for resource constrained devices (ethash murders your phone battery). Geth v1.9.0 ships a new mode for light clients, called an ultra light client. This mode aims to position itself midway on the security spectrum between a trusted server and a light server, replacing PoW verification with digital signatures from a majority of trusted servers.
With enough signatures from independent entities, you could achieve more than enough security for non-critical DApps. That said, ultra light client mode is not really meant for your average node, rather for projects wishing to ship Geth embedded into their own process. This work was spearheaded by Boris Petrov and Status.
Checkpoint oracle
Light clients are dirty little cheats! Instead of downloading and verifying each header from the genesis to chain head, they use a hard coded checkpoint (shipped within Geth) as a starting point. Of course, this checkpoint contains all the necessary infos to cryptographically verify even past headers, so security wise nothing is lost.
Still, as useful as the embedded checkpoints are, they do have their shortcomings:
- As the checkpoints are hard coded into our release binaries, older releases will always start syncing from an older block. This is fine for a few months, but eventually it gets annoying. You can, of course, update Geth to fetch a new checkpoint, but that also pulls in all our behavioral changes, which you may not want to do for whatever reason.
- Since these checkpoints are embedded into the code, you’re out of luck if you want to support them in your own private network. You’d need to either ship a modified Geth, or configure the checkpoints via a config file, distributing a new one whenever you update the checkpoint. Doable, but not really practical long term.
This is where Gary Rong’s and Zsolt Felföldi’s work comes in to play. Geth v1.9.0 ships support for an on-chain checkpoint oracle. Instead of relying on hard-coded checkpoints, light clients can reach out to untrusted remote light servers (peer-to-peer, no centralized bs) and ask them to return an updated checkpoint stored within an on-chain smart contract. The best part, light clients can cryptographically prove that the returned data was signed by a required number of approved signers!
Wait, how does a light client know who’s authorized to sign an on-chain checkpoint? For networks supported out of the box, Geth ships with hard coded checkpoint oracle addresses and lists of authorized signers (so you’re trusting the same devs who ship Geth itself). For private networks, the oracle details can be specified via a config file.
Although the old and new checkpoint mechanisms look similar (both require hard-coded data in Geth or a config file), the new checkpoint oracle needs to be configured only once and afterwards can be used arbitrarily long to publish new checkpoints.
checkpoint-admin
Ethereum contracts are powerful, but interacting with them is not for the faint of heart. Our checkpoint oracle contract is an especially nasty beast, because a) it goes out of its way to retain security even in the face of chain reorgs; and b) it needs to support sharing and proving checkpoints to not-yet-synced clients.
As we don’t expect anyone (not even ourselves) to manually interact with the checkpoint oracle, Geth v1.9.0 also ships an admin tool specifically for this contract, checkpoint-admin. Note, you’ll only ever need to care about this if you want to run your own checkpoint oracle for your own private network.
The checkpoint-admin can be used to query the status of an already deployed contract (–rpc needs to point to either a light node, or a full node with –lightserv enabled, both with the les RCP API namespace exposed):
$ checkpoint-admin --rpc ~/.ethereum/rinkeby/geth.ipc status Oracle => 0xebe8eFA441B9302A0d7eaECc277c09d20D684540 Admin 1 => 0xD9C9Cd5f6779558b6e0eD4e6Acf6b1947E7fA1F3 Admin 2 => 0x78d1aD571A1A09D60D9BBf25894b44e4C8859595 Admin 3 => 0x286834935f4A8Cfb4FF4C77D5770C2775aE2b0E7 Admin 4 => 0xb86e2B0Ab5A4B1373e40c51A7C712c70Ba2f9f8E Checkpoint (published at #4638418) 140 => 0x488c2eba92d31baeccfb6968fad5c21a3df93181b43b4cf253b4d572b64172ef
The admin command can also be used to deploy a new oracle, sign an updated checkpoint and publish it into the network. Furthermore, checkpoint-admin also works in offline mode (without a live chain to provide data) and can also be backed by clef for signing instead of using key files, but describing all these is for another day.
Monitoring
This is perhaps something that not many knew about, but since pretty much forever, Geth had built in support for monitoring different subsystems and events. Naturally, the original version was quite crude 🤣 (text UI, RPC reporting), but it provided the ground work. We can do better than this!
Metrics collection
First thing’s first, metrics need to be gathered before they can be exported and visualized. Geth can be instructed to collect all its known metrics via the –metrics CLI flag. To expose these measurements to the outside world, Geth v1.9.0 features 3 independent mechanisms: ExpVars, InfluxDB and Prometheus.
ExpVars are a somewhat custom means in the Go ecosystem to expose public variables on an HTTP interface. Geth uses its debug pprof endpoint to expose these on. Running Geth with –metrics –pprof will expose the metrics in expvar format at http://127.0.0.1:6060/debug/metrics. Please note, you should never expose the pprof HTTP endpoint to the public internet as it can be used to trigger resource intensive operations!
ExpVars are well-ish supported within the Go ecosystem, but are not the industry standard. A similar mechanism, but with a more standardized format, is the Prometheus endpoint. Running Geth with –metrics –pprof will also expose this format at http://127.0.0.1:6060/debug/metrics/prometheus. Again, please never expose the pprof HTTP endpoint to the public internet! Shoutout to Maxim Krasilnikov for contributing this feature.
Whereas ExpVars and Prometheus are pull based monitoring mechanisms (remote servers pull the data from Geth), we also support push based monitoring via InfluxDB (Geth pushes the data to remote servers). This feature requires a number of CLI flags to be set to configure the database connection (server, database, username, password and Geth instance tag). Please see the METRICS AND STATS OPTIONS section of geth help for details (–metrics.influxdb and subflags). This work was done by Anton Evangelatov.
Metrics visualization
Visualizing metrics can be a little daunting since you need to pick a charting program/service and put a whole lot of work into it to configure all the hosts, charts and dashboards.
We ourselves are using Datadog internally and have been contiguously tweaking our monitoring dashboards ever since we created them 1.5 years ago. If you are already using Datadog or are considering to do so, here’s a teaser of what you can assemble based on the metrics exposed by Geth (this is the dashboard through which we compare PRs against master):
Unfortunately Datadog does not support sharing dashboards with external entities (since they depend on how the monitored machines have been configured). As such, we can’t easily share the above work with you, but we did export a JSON dump of it in case anyone’s willing to follow in our footsteps!
Of course, we also understand that a paid service such as Datadog is not always ideal, especially if you are just starting out and don’t have money to burn on monitoring. A brilliant free monitoring tool is Grafana!
Maxim Krasilnikov made a Grafana dashboard a while ago against an older development version of Geth. We took his awesome work and merged into it the stats that we ourselves grew fond of in Datadog, resulting in quite a bit of extra work on Geth. The end result, however, is stunning (expect further updates over the next releases):
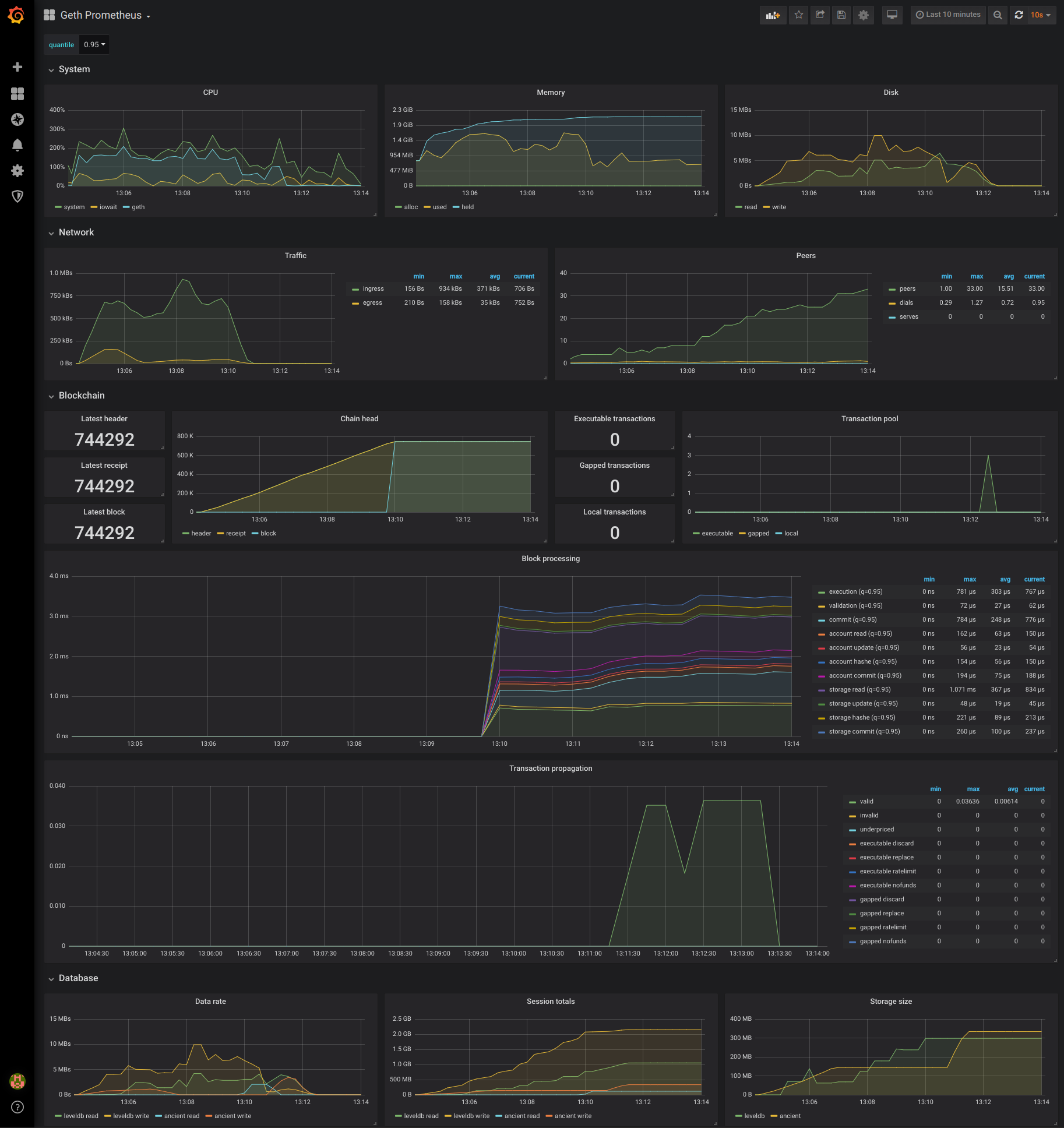
You can quickly reproduce the above charts via my clone of Maxim Krasilnikov’s project by running docker-compose up in the repo root and accessing http://localhost:3000 with the admin/admin credentials. Alternatively, you can view my testing snapshot on Raintank, or import this dashboard into your own Grafana instance
Puppeth explorer
A long time ago in a far away land, Puppeth saw the first light of day (specifically, in Mexico, just shy of two years ago). If you haven’t head about it, “Puppeth is a tool to aid you in creating a new Ethereum network down to the genesis block, bootnodes, signers, ethstats, faucet, wallet, explorer and dashboard”. Originally it was created to support deploying and maintaining the Rinkeby testnet, but has since been used by various groups for other private networks too.
Puppeth is not a tool for maintaining a high value production network, but it has, nonetheless, proven itself robust enough to keep Rinkeby relevant for over two years now! If you’d like a deeper dive into Puppeth, here’s my reveal talk from way back. In this post however lets focus on what’s new!
Puppeth is awesome! It allowed you since day 1 to deploy a full, operational Ethereum network across multiple machines, extended with a stats page to aid maintenance, along with a faucet and a dashboard to help onboard users easily. Puppeth, however, lacked a robust block explorer, since the only contenders back then were Etherscan and Etherchain, both closed source. We did hack something in, but it was kind of meh…
With the announcement of Blockscout late last year, everything changed! The Ethereum community finally got a real, open source block explorer, courtesy of the POA Network team. Compared to the established players, Blockscout of course has some catching up to do, but that does not stop us from realizing that it is already an insanely valuable asset. As such, Geth v1.9.0 ships a preliminary integration of Blockscout into Puppeth, filling a huge hole in our private network deployment tool!
This effort was pioneered by Gary Rong, but a huge shoutout goes to Ayrat Badykov too for his help in sorting out issues, questions and whatnot.
Please note, that we expect the initial integration to be rough (e.g. due to a “bug” in Blockscout, the Puppeth explorer will need to fully sync a Geth archive node before it can boot up the explorer web interface). By all means test it, run it, report any issues, but don’t be surprised if it goes down at 3AM!
Discovery protocol
Now here’s another piece of legacy infrastructure! Apart from a teeny-tiny modification, Ethereum’s discovery protocol has been specced, implemented and set in stone since pretty much forever. For those wondering what the discovery protocol is all about, it’s the mechanism through which a new node can find other Ethereum nodes on the internet and join them into a global peer-to-peer network.
So… what’s wrong with it then? Didn’t it work well enough until now? If it ain’t broken, don’t fix it and all that?
Well, Ethereum’s original discovery protocol was made for a different time, a time when there was only one chain, when there weren’t private networks, when all nodes in the network were archive nodes. We outgrew these simplistic assumptions, which although is a success story, it also brings new challenges:
- The Ethereum ecosystem nowadays has many public, private and test networks. Although Ethereum mainnet consists of a large number of machines, other networks are generally a lot smaller (e.g. Görli testnet). The discovery protocol doesn’t differentiate between these networks, so connecting to a smaller one is a never ending trial and error of finding unknown peers, connecting to them, then realizing they are on a different network.
- The same original Ethereum network can end up partitioning itself into multiple disjoint pieces, where participants might want to join one piece or the other. Ethereum Classic is one of the main examples here, but a similar issue arises every time a network upgrade (hard fork) passes and some nodes upgrade late. Without information concerning the rules of the network, we again fall back to trial and error connectivity, which is computationally extremely expensive.
- Even if all nodes belong to the same network and all nodes adhere to the same fork rules, there still exists a possibility that peering is hard: if there is connectivity asymmetry, where some nodes depend on services offered by a limited subset of machines (i.e. light clients vs. light servers).
Long term we’re working towards a brand new version of the discovery protocol. Geth’s light clients have been since forever using a PoC version of this, but rolling out such a major change for the entire Ethereum network requires a lot of time and a lot of care. This effort it being piloted primarily by Felix Lange and Frank Szendzielarz in collaboration with Andrei Maiboroda from Aleth/C++, Antoine Toulme with Java, Age Manning from Lighthouse/Rust and Tomasz Stańczak from Nethermind/C#.
Ethereum Node Records
The above was a whole lot of text about something we didn’t ship! What we did ship however, is the Ethereum Node Record (ENR) extension of the new discovery protocol, which can actually run on top of the old protocol too! An ENR is a tiny, 300 byte, arbitrary key-value data set, that nodes can advertise and query via discovery. Although the new discovery protocol will provide fancy ways of sharing these in the network, the old protocol too is capable of directly querying them.
The immediate benefit is that nodes can advertise a lot of metadata about themselves without an expensive TCP + crypto handshake, thus allowing potential peers to filter out unwanted connections without ever making them in the first place! All credits go to Felix Lange for his unwavering efforts on this front!
Ok, ok, we get it, it’s fancy. But what is it actually, you know, useful for, in human-speak?
Geth v1.9.0 ships two extensions to the discovery protocol via ENRs:
- The current discovery protocol is only capable of handling one type of IP address (IPv4 or IPv6). Since most of the internet still operates on IPv4, that’s what peers advertise and share with each other. Even though IPv6 is workable, in practice you cannot find such peers. Felix Lange’s work on advertising both IPv4 and IPv6 addresses via ENRs allows peers to discover and maintain Kademlia routing tables for both IP types. There’s still integration work to be done, but we’re hoping to elevate IPv6 to a first class citizen of Ethereum.
- Finding a Rinkeby node nowadays works analogously to connecting to random websites and checking if they are Google or not. The discovery protocol maintains a soup of internet addresses that speak the Ethereum protocol, but otherwise has no idea which chain or which forks they are on. The only way to figure out, is to connect and see, which is a very expensive shooting-in-the-dark. Péter Szilágyi proposed an extension to ENR which permits nodes to advertise their chain configuration via the discovery protocol, resulting in a 0-RTT mechanism for rejecting surely bad peers.
The most amazing thing however with ENR – and its already implemented extras – is that anyone can write a UDP crawler to index Ethereum nodes, without having to connect to them (most nodes won’t have free slots; and crawlers that do connect via TCP waste costly resources). Having simple access to all the nodes, their IPs/ports, capabilities and chain configurations permits the creation of a brand new discovery protocol based on DNS, allowing nodes with blocked UPD ports (e.g. via Tor) to join the network too!
Bootnodes
We’ve had a varying number of bootnodes of varying quality, managed by varying people since the Frontier launch. Although it worked well-ish, from a devops perspective it left a lot to desire, especially when it came to monitoring and maintenance. To go along our Geth v1.9.0 release, we’ve decided to launch a new set of bootnodes that is managed via Terraform and Ansible; and monitored via Datadog and Papertrail. We’ve also enabled them to serve light clients, hopefully bumping the reliability of the light protocol along the way. Huge shoutout to Rafael Matias for his work on this!
Our new list of bootnodes is:
- enode://d860a01f9722d78051619d1e2351aba3f43f943f6f00718d1b9baa4101932a1f5011f16bb2b1bb35db20d6fe28fa0bf09636d26a87d31de9ec6203eeedb1f666@18.138.108.67:30303 (Singapore, AWS)
- enode://22a8232c3abc76a16ae9d6c3b164f98775fe226f0917b0ca871128a74a8e9630b458460865bab457221f1d448dd9791d24c4e5d88786180ac185df813a68d4de@3.209.45.79:30303 (Virginia, AWS)
- enode://ca6de62fce278f96aea6ec5a2daadb877e51651247cb96ee310a318def462913b653963c155a0ef6c7d50048bba6e6cea881130857413d9f50a621546b590758@34.255.23.113:30303 (Ireland, AWS)
- enode://279944d8dcd428dffaa7436f25ca0ca43ae19e7bcf94a8fb7d1641651f92d121e972ac2e8f381414b80cc8e5555811c2ec6e1a99bb009b3f53c4c69923e11bd8@35.158.244.151:30303 (Frankfurt, AWS)
- enode://8499da03c47d637b20eee24eec3c356c9a2e6148d6fe25ca195c7949ab8ec2c03e3556126b0d7ed644675e78c4318b08691b7b57de10e5f0d40d05b09238fa0a@52.187.207.27:30303 Australia, Azure)
- enode://103858bdb88756c71f15e9b5e09b56dc1be52f0a5021d46301dbbfb7e130029cc9d0d6f73f693bc29b665770fff7da4d34f3c6379fe12721b5d7a0bcb5ca1fc1@191.234.162.198:30303 (Brazil, Azure)
- enode://715171f50508aba88aecd1250af392a45a330af91d7b90701c436b618c86aaa1589c9184561907bebbb56439b8f8787bc01f49a7c77276c58c1b09822d75e8e8@52.231.165.108:30303 (South Korea, Azure)
- enode://5d6d7cd20d6da4bb83a1d28cadb5d409b64edf314c0335df658c1a54e32c7c4a7ab7823d57c39b6a757556e68ff1df17c748b698544a55cb488b52479a92b60f@104.42.217.25:30303 (West US, Azure)
Our legacy bootnodes will continue to function for the time being, but will be gradually sunset in the following months.
Other changes
Beside all the awesome features enumerated above, there are a few other notable changes that are not large enough to warrant their own section, but nonetheless important enough to explicitly mention.
RPC APIs:
- The origin check on WebSocket connections (–wsorigins) is enforced only when the Origin header is present. This makes it easier to connect to Geth from non-browser environments such as Node.js, while preventing use of the RPC endpoint from arbitrary websites.
- You can set the maximum gas for eth_call using the –rpc.gascap command line option. This is useful if exposing the JSON-RPC endpoint to the Internet.
- All RPC method invocations are now logged at debug level. Failing methods log as warning so you can always see when something isn’t right.
- Geth v1.9.0 supports the eth_chainId RPC method defined in EIP 695.
Networking:
- The default peer count is now 50 instead of 25. This change improves sync performance.
- A new CLI tool (cmd/devp2p) was added to the source tree for for debugging P2P networking issues. While we don’t distribute this tool in the alltools archive yet, it’s already very useful to check issues with peer discovery.
- The P2P server now rejects connections from IPs that attempt to connect too frequently.
Miscellaneous:
- A lot of work has gone into improving the abigen tool. Go bindings now support Solidity struct and function pointer arguments. The Java generator is improved as well. The mobile framework can create deploy transactions.
- Significant parts of the go-ethereum repo now build without CGO. Big thanks to Jeremy Schlatter for this work.
Compatibility
Although Go Ethereum v1.9.0 brings an impressive number of improvements, there are a few backwards incompatible changes too. This section is a rundown of all the things that got changed or sunset in the release:
- Account unlocking with open HTTP, WebSocket or GraphQL ports have been disallowed due to security reasons. Power users can restore the old behavior with the –allow-insecure-unlock CLI flag at their own risk.
- The old Ubuntu docker images and the old (monolithic) Alpine docker images have been removed as deprecated over a year ago. Unless you configured your cluster in 2016, you most probably used the slim Alpine images and are safe.
- The original geth monitor CLI command was removed along with its supporting debug_metrics RPC API endpoint. Anyone relying on monitoring should use the ExpVar, InfuxDB or Prometheus metrics reporting along with Datadog or Grafana.
- The geth bug CLI command has been removed, being an unnecessary nicety. If you encounter a bug, you can simply open an issue on our GitHub tracker and fill out the template manually.
- The les/1 and eth/62 protocols were removed. les/1 was only supported by Geth and everyone on Constantinople runs les/2 already. eth/62 was deprecated even before Frontier, but was left in for cpp-ethereum.
- Google+ authentication has been removed from the Puppeth faucet since Google sunset its social network in the beginning of April, 2019.
- The Ledger HD wallet derivation path was updated from the orignal legacy path to the canonical ecosystem one. Accounts from old paths will still be discovered.
- The default cache allowance is chosen dynamically based on the network and sync modes. Mainnet full nodes default to 4GB, testnet and private networks to 1GB. Light clients default to 128MB. Explicit –cache is of course honored.
- The PoW calculation in Whisper v6 was incompatible with Parity due to not fully adhering to the spec. This was fixed, but it also means that Whisped v6 shipped with Geth v1.9.0 is incompatible with previous versions.
- The –lightserv and –lightpeers flags were renamed to –light.serve and –light.maxpeers respectively. The old versions are deprecated, but will continue to work for the next year or so.
- The default datadir on Windows is now derived from the LocalAppData environment variable. The old location in $HOME/AppData/Roaming is still recognized. The location change works better with Cygwin and setups using remote user accounts.
- The JSON-RPC server has been rewritten and now supports bi-directional communication. You can expose method handlers on the client side using the rpc.Client.RegisterName method. While we did test this extensively, there may be compatibility issues with the new server. Please report any RPC issues you find.
Epilogue
We’re really proud of this release! It took a lot longer than expected, but we wanted to ship all the breaking changes in one go to minimize potential surprises (upgrade issues); and to finalize the APIs of new features, to avoid breaking them later. Hope you too will find a gem for yourself among our shipped ~370 changes.
As with all our previous releases, you can find the:
And as a last word before signing off (better twice than none):
Warning: We’ve tried our best to squash all the bugs, but as with all major releases, we advise everyone to take extra care when upgrading. The v1.9.0 release contains database schema changes, meaning it’s not possible to downgrade once updated. We also recommend a fresh fast sync as it can drastically reduce the database size.
[ad_2]
Source link




 Bitcoin
Bitcoin  Tether
Tether  XRP
XRP  USDC
USDC  Dogecoin
Dogecoin  LEO Token
LEO Token {kind=link}
{kind=link}
{kind=link}